# 技能开发教程
这份文档是给**技术人员**看的,目标不是解释概念,而是让你拿到 `skill-template` 后,可以**一步一步开发出一个新的 skill**。
本文默认你开发的是当前最常见的一类技能:
- 有明确的 `scripts/main.py` CLI 入口
- 可能需要读写本地 SQLite
- 可能需要调用兄弟技能
- 业务逻辑主要放在 `scripts/service/`
如果你开发的是发布型 skill,这个模板就是直接可用的起点。
## 推荐 AI 开发工具
当前 skill 开发建议尽量配合 AI 编程工具使用。这样做不是为了替代技术人员,而是为了提升以下环节的效率:
- 搭建标准目录结构
- 生成样板代码
- 理解旧项目代码
- 批量补文档、注释和测试
- 辅助排查报错与重构代码
建议团队统一选择 1 到 2 个主力工具长期使用,避免每个人工具链差异太大,导致协作方式不一致。
下面先列国外主流工具,再列国内主流工具。链接优先使用官方站点、官方文档或官方安装入口。
### 国外主流工具
| 工具 | 类型 | 适合场景 | 官方入口 |
|------|------|----------|----------|
| Cursor | 独立 AI IDE | 代码编辑、Agent 开发、整仓理解 | 官网 / 下载 |
| Windsurf | 独立 AI IDE | Agent 编程、项目生成、连续开发流 | 文档 / 下载 |
| GitHub Copilot | IDE 插件 / 编程助手 | 日常补全、解释代码、生成函数、配合 VS Code 或 JetBrains 使用 | 官网 |
| Claude Code | 终端 / IDE 编程代理 | 命令行开发、代码库分析、自动改代码、运行命令 | 官网 / 文档 |
| Codex | 终端 / IDE / Web 编程代理 | OpenAI 官方编码代理,适合代码生成、理解、调试、评审 | 官网 / 快速开始 |
| Aider | 终端 AI 编程工具 | 已有代码仓库的增量开发、终端协作、快速提交 | 官网 / 文档 |
| Cline | VS Code / JetBrains 插件 | 编辑器内 Agent 开发、命令执行、浏览器联动调试 | 官网 / 文档 / VS Code 插件 |
### 国内主流工具
| 工具 | 类型 | 适合场景 | 官方入口 |
|------|------|----------|----------|
| Trae | 独立 AI IDE | AI 辅助写代码、项目搭建、对话式开发 | 官网 / 下载 |
| 通义灵码 | 独立 IDE / IDE 插件 | 国内团队日常编码、问答、补全、代码生成 | 官网 / 下载 |
| CodeGeeX | IDE 插件 / 开源助手 | 代码补全、生成、注释、跨语言辅助 | GitHub / VS Code 插件 |
| 腾讯 CodeBuddy | IDE 插件 | 代码补全、测试生成、智能问答、腾讯云开发体系协作 | 官网 / 文档 / VS Code 插件 |
| 百度文心快码(Baidu Comate) | IDE 插件 | 国内研发团队辅助编码、解释、测试、优化 | 官网 |
### 选型建议
如果你们团队主要做这类 Python skill 开发,我建议这样选:
- 想要一体化最强体验:优先试 `Cursor` 或 `Windsurf`
- 想要命令行深度协作:优先试 `Claude Code` 或 `Aider`
- 想继续基于 VS Code 插件体系:优先试 `GitHub Copilot`、`Cline`、`通义灵码`、`CodeBuddy`
- 想优先使用国内生态与中文支持:优先试 `Trae`、`通义灵码`、`CodeGeeX`、`CodeBuddy`、`文心快码`
### 团队落地建议
为了减少培训成本,建议内部至少统一一套主工具方案:
- 国外方案:`Cursor` + `Claude Code`
- 国内方案:`Trae` + `通义灵码`
- VS Code 插件方案:`GitHub Copilot` + `Cline`
不建议每位技术人员完全自由发挥,否则后续在:
- 提示词写法
- 代码修改习惯
- 调试方式
- 提交节奏
这些方面会越来越不统一。
## 1. 先理解模板的定位
`skill-template` 不是业务 skill,它只是一个**新 skill 仓库模板**。
你不应该直接在这个仓库里开发业务,而应该:
1. 复制这个目录
2. 改成新 skill 的目录名
3. 把占位内容替换掉
4. 再开始写业务逻辑
## 2. 新 skill 的标准目录结构
复制模板后,你应该保留下面这套结构:
```text
your-skill/
├─ .github/
├─ assets/
├─ evals/
├─ references/
├─ scripts/
│ ├─ cli/
│ ├─ db/
│ ├─ jiangchang_skill_core/
│ ├─ service/
│ └─ util/
├─ tests/
├─ .gitignore
├─ README.md
├─ release.ps1
└─ SKILL.md
```
各目录职责如下:
- `assets/`:放示例输出、schema、静态说明资源
- `references/`:放研发和编排需要长期维护的文档
- `scripts/`:放真正的代码
- `tests/`:放自动化测试
- `evals/`:放人工验收材料、评估清单、示例场景
## 3. `scripts/` 内部如何分层
`scripts/` 不是乱放 Python 文件,而是按职责分层:
```text
scripts/
├─ main.py
├─ cli/
├─ db/
├─ jiangchang_skill_core/
├─ service/
└─ util/
```
每层的职责要明确:
- `main.py`
作用:唯一 CLI 入口
只做启动、编码兼容、引入 `cli.app`
- `cli/`
作用:参数解析、命令分发、用法说明
不写具体业务逻辑
- `db/`
作用:SQLite 连接、建表、repository
不写页面操作和业务编排
- `service/`
作用:核心业务逻辑
比如发布流程、调用兄弟技能、浏览器自动化
- `util/`
作用:常量、日志、路径、时间工具、通用帮助函数
- `jiangchang_skill_core/`
作用:运行时环境与统一日志副本
一般按现有规范技能复制,不要自己乱改结构
## 4. 开发一个新 skill 的标准步骤
下面这套顺序建议严格按步骤做,不要一上来就直接写 `service`。
### 第一步:复制模板并改目录名
例如你要开发 `weibo-publisher`:
1. 复制 `skill-template`
2. 新目录改成 `weibo-publisher`
3. 初始化为独立 git 仓库
4. 关联它自己的远端仓库
目录名要和 skill slug 对齐,后面很多地方都依赖这个命名。
### 第二步:先改 4 个最关键的标识
复制后优先改下面这些地方:
1. `SKILL.md`
2. `scripts/util/constants.py`
3. `references/` 下的文案
4. `scripts/service/` 下的平台占位文件名
最先要统一的是:
- 技能中文名
- `slug`
- 平台中文名
- 平台内部键
- 日志 logger 名
此外,如果该技能发布后默认不公开(`access_scope = 0`),建议一开始就把 `SKILL.md` 中的 `metadata.openclaw.developer_ids` 配好。这样后续发布到平台时,开发者本人仍能在技能市场中看到并验证该技能。
## 5. 哪些占位内容必须替换
复制后,至少要全局检查并替换下面这些内容:
- `your-skill-slug`
- `your-platform-key`
- `技能开发模板(复制后请修改)`
- `你的平台名`
- `platform_playwright.py`
- `openclaw.skill.your_skill_slug`
如果你是做发布型 skill,通常还要替换:
- `publish` 命令中的中文提示
- `references/CLI.md` 的命令示例
- `references/README.md` 的用户话术
- `references/SCHEMA.md` 的数据库文件名
## 6. `SKILL.md` 应该怎么写
`SKILL.md` 是技能清单,不是设计文档。
应该重点写:
- 技能名称
- 技能描述
- `slug`
作用:技能的唯一英文标识,通常用于仓库名、发布包名、运行时目录名、平台主键匹配等
示例:`weibo-publisher`、`douyin-publisher`、`xiaohongshu-publisher`
- `category`
作用:技能在平台中的分类,用于市场展示与归类,不是代码内部键
示例:`通用`、`内容`、`办公协作`、`物流`、`抖音`、`小红书`
- `developer_ids`(如需给非公开技能自动补开发者可见权限)
作用:声明发布后默认拥有可见权限的开发者用户 ID 列表
- `dependencies`
作用:声明该技能依赖的兄弟技能或运行前置能力,便于平台或编排层识别依赖关系
示例:
```yaml
dependencies:
required:
- account-manager
- content-manager
```
- 何时使用本技能
- 对用户的引导话术
- CLI 使用原则
不要在 `SKILL.md` 里写大量实现细节。
实现细节放在:
- `references/`
- 代码注释
- `service/` 实现里
### 关于 `metadata.openclaw.developer_ids`
这是一个平台发布元数据字段,用于解决下面这个问题:
- 技能发布后若平台记录中的 `access_scope = 0`,技能默认不公开
- 如果不额外授权,连开发者自己也可能在技能市场里看不到这个技能
因此可以在 `SKILL.md` 中声明:
```yaml
metadata:
openclaw:
slug: your-skill-slug
category: 通用
developer_ids:
- 1032
- 12428
```
约定如下:
- 只允许填写正整数用户 ID
- 推荐使用数组,即使当前只有 1 个开发者
- 发布时平台会把这些用户自动补写到 `skill_user_access`
- 第一个 ID 会同步到 `skills.developer_id`
- 一期只做“补授权”,不会因为你 later 修改数组而自动撤销旧授权
## 7. `references/` 应该放什么
`references/` 是当前规范 skill 的文档中心,建议至少有这些:
- `README.md`
面向内部说明和技能作用介绍
- `CLI.md`
写清楚命令、参数、默认值、兄弟技能调用方式
- `RUNTIME.md`
写清楚运行时目录、环境变量、入口约定
- `SCHEMA.md`
写清楚数据库路径、核心表结构、日志表结构
- `DEVELOPMENT.md`
写给技术人员的开发教程,也就是本文档
如果后面某个 skill 需要更细的说明,可以再加:
- `ERRORS.md`
- `INTEGRATION.md`
- `PLATFORMS.md`
## 8. `assets/` 应该放什么
`assets/` 不放业务代码,只放辅助材料。
建议放:
- `examples/`
比如 `version` 输出示例、`log-get` 输出示例
- `schemas/`
比如日志记录、机读 JSON 的 schema
不要把正式研发文档放到 `assets/`。
文档应该进 `references/`。
## 9. `cli` 层怎么写
建议保持一个原则:
- `cli` 只负责解析参数和路由
- `service` 才负责干活
也就是说,`cli/app.py` 的职责是:
1. 打印帮助
2. 定义 `publish / logs / log-get / health / version`
3. 把参数转交给 `service.publish_service`
不要在 `cli/app.py` 里直接写:
- 浏览器自动化
- 子进程调用兄弟技能
- SQLite 逻辑
## 10. `service` 层怎么写
`service` 是核心层。
通常可以这样拆:
- `publish_service.py`
放命令编排、参数兜底、结果分流
- `sibling_bridge.py`
放兄弟技能调用,例如调 `account-manager`、`content-manager`
- `*_playwright.py`
放浏览器后台自动化
- `entitlement_service.py`
放鉴权逻辑
### 一个很重要的原则
不要把所有逻辑都堆进一个文件。
推荐流向是:
`cli.app` -> `service.publish_service` -> `service.sibling_bridge` / `service.xxx_playwright` -> `db`
## 11. `db` 层怎么写
如果你的 skill 需要记录日志或本地状态,建议:
- `db/connection.py`
只做连接和建表
- `db/publish_logs_repository.py`
只做增删查改
不要在 `db` 层里:
- 调浏览器
- 打印用户提示
- 拼接业务流程
## 12. 如何接兄弟技能
如果 skill 要依赖兄弟 skill,不要在业务代码里写死绝对路径。
统一通过:
- `scripts/util/runtime_paths.py`
- `scripts/service/sibling_bridge.py`
来做调用。
常见调用对象是:
- `account-manager`
- `content-manager`
调用原则:
1. 通过 `get_skills_root()` 找到兄弟技能根目录
2. 再拼出对应 `scripts/main.py`
3. 用子进程调用
4. 机器可读输出优先 JSON
## 13. 如何开发一个新 skill
不管你开发的是发布类、采集类、分析类还是知识库类 skill,建议都先按下面这个顺序推进:
1. 先把目录结构搭完整
2. 先让 `health` / `version` 跑通
3. 再把核心 `service` 骨架跑通
4. 再接兄弟技能桥接、数据库或外部系统
5. 最后再补浏览器自动化、复杂流程编排或高风险集成
不要一开始就直接写页面选择器、复杂接口编排或深层业务逻辑。
推荐先确保这些基础能力正常:
- CLI 入口能跑通
- 基础命令输出稳定
- 关键依赖能取到
- 日志或本地状态能落下来
- 错误返回值格式定好了
如果你的 skill 恰好是 publisher 类,可以把上面的“核心 `service`”具体落成 `publish_service.py`,再逐步接 `sibling_bridge.py`、`*_playwright.py`。但这只是示例,不代表模板只适合发布类技能。
## 14. 本地开发的最小验证顺序
建议每次新 skill 开发时按下面顺序验证:
### 1. 验证入口
```bash
python scripts/main.py health
python scripts/main.py version
```
### 2. 验证 CLI 路由
```bash
python scripts/main.py -h
python scripts/main.py -h
```
### 3. 验证本地日志与数据库
如果你的 skill 需要本地日志或数据库,再继续:
```bash
python scripts/main.py
python scripts/main.py
```
如果你沿用了模板中的发布型骨架,那么这里可以具体对应成:
```bash
python scripts/main.py logs
python scripts/main.py log-get 1
```
### 4. 最后再验证真实业务
比如:
```bash
python scripts/main.py
```
## 15. 发布到正式环境验证
当本地开发、自测和联调完成后,还需要把 skill 发布到正式环境做一次完整验证。建议技术人员严格按下面顺序执行,不要跳步。
### 第一步:在 skill 根目录执行 `release.ps1`
在当前 skill 仓库根目录执行:
```powershell
.\release.ps1
```
如果你的技能使用了 `metadata.openclaw.developer_ids`,那么这一步触发的发布工作流除了同步 `skills` / `skill_versions` 外,还会在平台侧自动补开发者可见权限。测试非公开技能时,建议重点验证这部分是否生效。
这一步会自动完成标准发布动作,包括:
1. 检查当前仓库状态
2. 自动提交尚未提交的改动
3. 推送最新代码到远程仓库
4. 自动创建新的语义化版本 tag
5. 推送 tag,触发后续 CI 流程
如果你只是想先预览发布动作,可以先执行:
```powershell
.\release.ps1 -DryRun
```
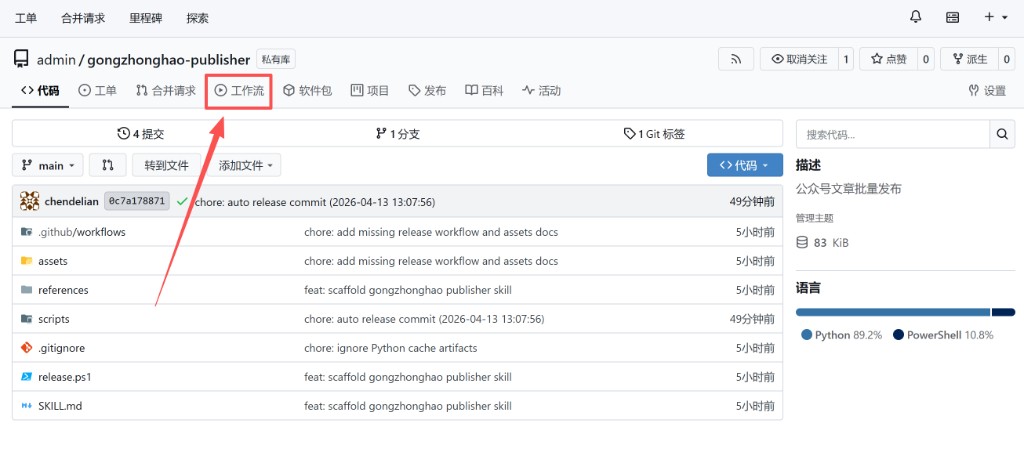
### 第二步:到 Gitea 仓库查看工作流
发布命令执行完成后,远程仓库会自动触发 Gitea 工作流。此时应立即进入对应 skill 的仓库页面,切换到“工作流”页签查看执行状态。
重点确认:
- 是否已经出现最新一次发布记录
- 是否由最新提交触发
- 是否成功执行完 `release_skill.yaml`
下面这张图演示了在仓库页进入“工作流”的位置:
下面这张图演示了工作流成功后的状态页面:
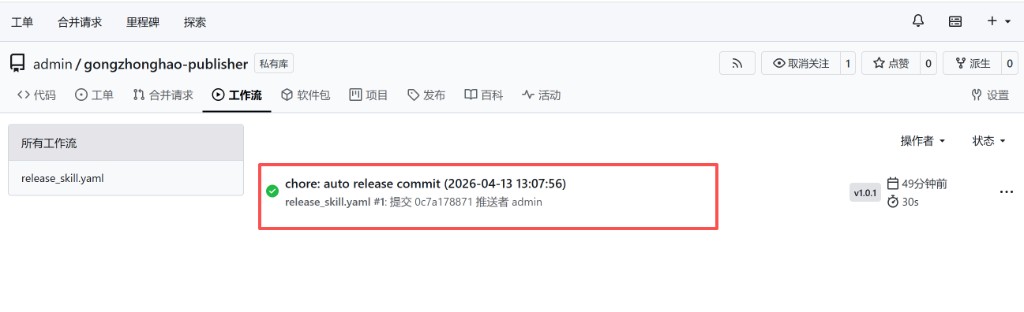
### 第三步:确认工作流执行成功
只有当工作流状态为成功,才说明正式发布产物已经正确构建完成。
如果工作流失败,不要继续做平台验证,而应该先回到代码仓库排查,例如:
- 发布脚本是否正常推送
- `SKILL.md`、`scripts/`、`references/` 是否齐全
- 工作流文件是否存在
- 发布包结构是否符合模板规范
### 第四步:进入匠厂平台下载安装包
当工作流成功后,就可以进入匠厂平台验证最终安装效果。
匠厂产品下载地址:
- [https://jc2009.com/product.html](https://jc2009.com/product.html)
打开页面后,下载并安装匠厂客户端。下面这张图演示了下载入口位置:
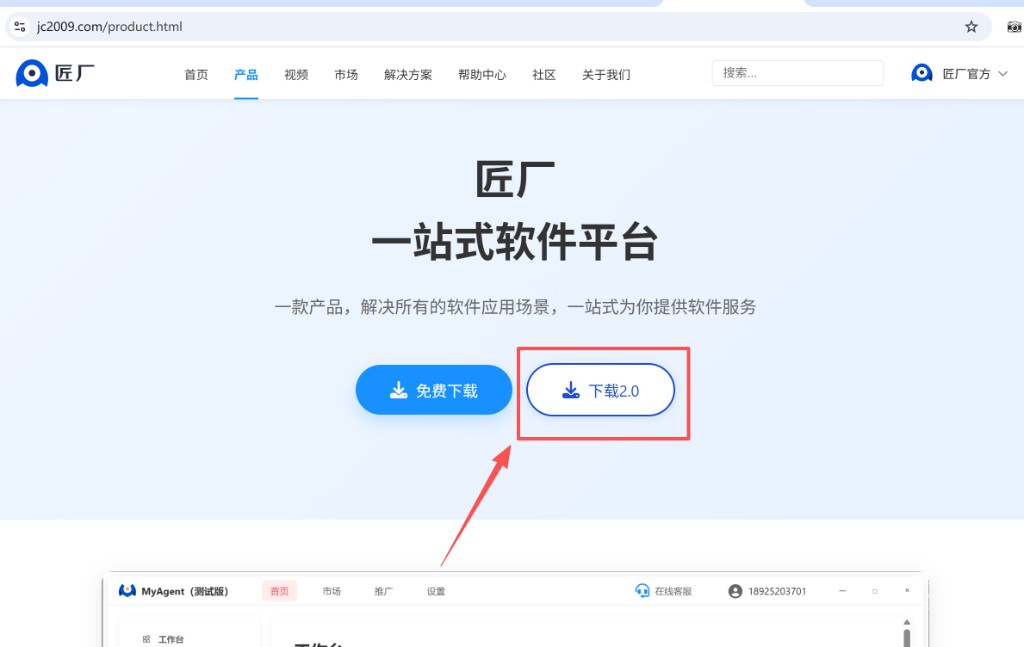
匠厂产品页可从这里进入:[产品下载 - 匠厂](https://jc2009.com/product.html)
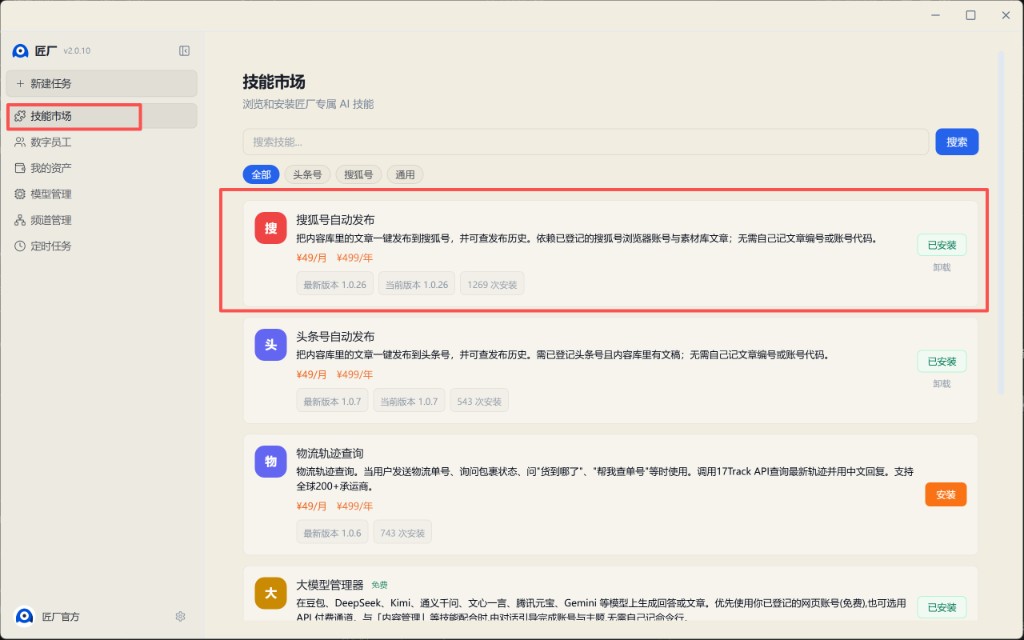
### 第五步:安装匠厂后,在技能市场检查最新 skill
安装并启动匠厂后,进入左侧“技能市场”,搜索或查找刚刚发布的 skill,确认以下内容:
- 技能可以被正常检索到
- 技能名称、说明、版本信息正确
- 最新版本已经同步出来
- 可以正常安装或更新
下面这张图演示了在技能市场中查看已发布 skill 的位置:
### 第六步:安装并实际启用该 skill
在技能市场中找到目标 skill 后,执行安装或更新操作,确保客户端本地已经拿到最新版本。
这一步建议至少确认:
- 安装按钮可以正常执行
- 安装后状态正常
- 不会出现缺文件、缺入口或安装失败的问题
### 第七步:在“新建任务”中实际使用该 skill
安装完成后,不要只停留在“已安装”状态,还需要进入“新建任务”页面,真正调用一次该 skill,完成最终验证。
建议至少验证:
- 新任务中可以正常选择或触发该 skill
- skill 能被正确唤起
- 主要命令或主流程可以运行
- 返回结果、日志和行为符合预期
下面这张图演示了安装后在任务界面中实际使用 skill 的场景:
## 16. 发布前检查清单
每个新 skill 发布前,建议技术人员逐条确认:
- [ ] 目录结构符合当前模板
- [ ] `SKILL.md` 中 slug、名称、描述都已替换
- [ ] `scripts/util/constants.py` 已修改
- [ ] `references/CLI.md` 示例命令已改成真实命令
- [ ] `service` 下的平台文件名已改对
- [ ] 没有残留旧平台名
- [ ] `health` / `version` 可运行
- [ ] `.gitignore` 生效,没有把 `__pycache__` 提交进去
- [ ] `release.ps1` 存在
- [ ] `.github/workflows/release_skill.yaml` 存在
## 17. 常见错误
### 错误 1:只改了目录名,没改 slug
表现:
- 数据目录不对
- 版本输出不对
- 日志名不对
要检查:
- `SKILL.md`
- `scripts/util/constants.py`
### 错误 2:平台中文名改了,内部键没改
表现:
- 兄弟技能筛选账号失败
- 发布命令走错平台
要检查:
- `publish_service.py`
- `sibling_bridge.py`
- `references/CLI.md`
### 错误 3:把业务逻辑写进 CLI
表现:
- 文件越来越乱
- 不方便测
- 参数和业务耦合太重
要改回:
- `cli` 只做参数解析
- `service` 才做业务
### 错误 4:保留了旧模板结构
表现:
- 仓库同时存在 `docs/`、`optional/`、`skill_main.py`
- 技术人员不知道看哪一套
现在的新模板原则是:
- 不做旧结构兼容
- 统一走 `references/` + `scripts/main.py`
## 18. 推荐开发顺序总结
如果让一个新人照着做,我建议他按这个顺序:
1. 复制模板并改目录名
2. 改 `SKILL.md`
3. 改 `scripts/util/constants.py`
4. 改 `references/`
5. 改 `scripts/cli/app.py`
6. 改 `scripts/service/`
7. 跑 `health` / `version`
8. 再做业务联调
9. 最后 release
## 19. 这份模板的底线要求
以后新建 skill,至少要满足这几点:
- 目录结构统一
- 入口统一为 `scripts/main.py`
- 文档统一放 `references/`
- 业务核心逻辑统一放 `scripts/service/`
- 不再使用旧模板历史结构
如果做不到这些,后面 skill 一多,就会越来越乱。